
Trabajar NLP basico con spacy
Spacy es una herramienta para trabajar problemas relacionados con lenguaje, con un amplio soporte de lenguajes provee una sintaxis intuitiva para operar en ambitos linguisticos.
Modelos
Los modelos en spacy son modulos preentrenados a travez de Convolutional Neural Networks, se dividen en modelos bases y modelos iniciales. Los primeros son claves para inferir caracteristicas linguisticas de los datos, y se clasifican en general en dependencia del idioma. Los segundo son paquetes iniciales con valores ponderados para continuar entrenando otras arquitecturas que puedan resultar mas convenientes deacuerdo al contexto del problema.
Cargar los modelos que se utilizaran para procesar texto, es_core_news_*. SM se refiere a modelos reducidos, mas rapidos sin embargo menos precisos. MD sin modelos medios entrenados con mayor datos y mayor precision.
Mas informacion en Modelos en español de Spacy
!python -m spacy download es_core_news_sm
!python -m spacy download es_core_news_mdimport spacy
import es_core_news_sm
import es_core_news_md
nlp = es_core_news_sm.load()
doc = nlp('''Un desastroso espirítu posee tu tierra:
donde la tribu unida blandió sus mazas,
hoy se enciende entre hermanos perpetua guerra,
se hieren y destrozan las mismas razas.''')
for token in doc: print(token.text, "|", token.lemma_, '|', token.pos_)Un | Un | DET
desastroso | desastroso | NOUN
espirítu | espirítu | PROPN
posee | poseer | VERB
tu | tu | DET
tierra | tierra | NOUN
: | : | PUNCT
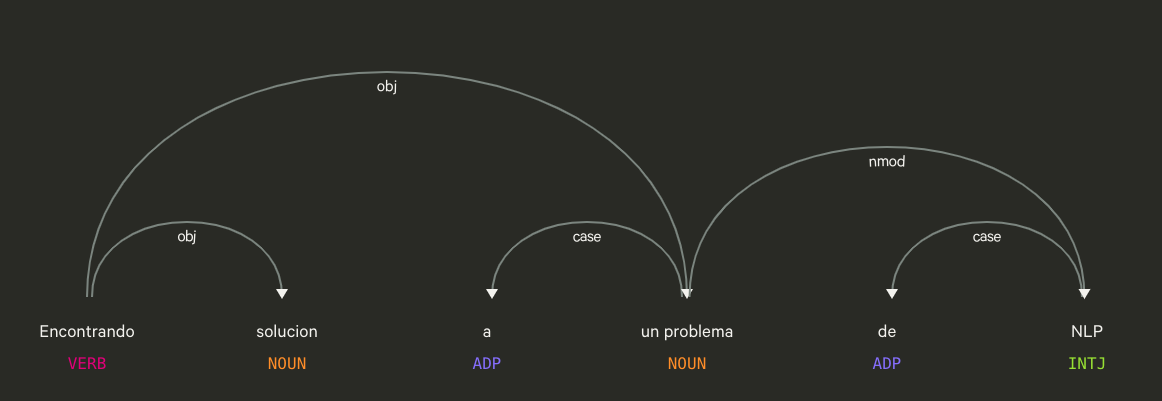
Flujo de texto a documento
Cuando se ejecuta una llamada a nlp, spacy utiliza un numero de modulos especializados para producir un documento analizado. Cada una de las secciones puede ser extendida y/o deshabilitada si fuera necesario. El flujo del texto se divide en las siguientes secciones:
-
Tokenizer: el modulo que se encarga de tomar un texto y dividirlo en unidades atomicas, para lenguaje indo-europeos generalmente los espacios en blanco suelen ser relativamente correcto, sin embargo Spacy realiza una division mas integral. Por ejemplo toma en cuenta simbolos de puntuacion para realizar la tokenizacion
Objective-Cseria separado comoObjective,-,C. -
Tagger: Asigna el Part-Of-Speech con un modelo probabilistico. Este paso es esencial para tecnicas mas complejas que generalmente dependen de saber la estructura de la oracion.
-
NER: Reconocimiento de entidad se utiliza para analizar un texto y detectar tipos especificos de cadenas, este proceso puede ser altamente personalizado en dependencia del contexto.

Las herramientas graficas para visualizar los arboles de dependencias estructura pueden ser utilizes para realizar discriminadores de palabras utiles, como describiremos luego
from spacy import displacy
from IPython.display import SVG
doc = nlp("Jose Ayerdis es un desarrollador que trabaja en procesamiento de lenguaje natural, con una maestria en Universidad de Buffalo, Nueva York.")
SVG(data = displacy.render(doc))Reconocimiento de entidad
Generalmente una tarea costosa al momento de realizar analisis de texto, existen muchas tecnicas para automaticamente detectar entidades de valor dentro de una cadena corta, Spacy aunque no es perfecto y esta tarea es muy dependiente del contexto, es posible obtener buenos resultados para generar un dataset y reentrenar un modelo para realizar un reconocimiento de entidades mas a la medida. Spacy named entities
https://spacy.io/usage/linguistic-features#named-entities
nlp_md = es_core_news_md.load()
article_text = '''La ONG Fundación del Río explicó este viernes que la decisión de la Organización de la ONU para la Educación, la Ciencia y la Cultura (Unesco) de declarar como geoparque el río Coco, ubicado en el norte de Nicaragua, obliga a las autoridades nicaragüenses a proteger su ecosistema, ya que se encuentra en el área más deforestada de la cuenca. La Unesco está reconociendo la importancia del río Coco, pero también está haciendo un llamado al Gobierno a que actúe en la protección y la conservación de esos ecosistemas, dijo a Efe el presidente de la Fundación del Río, Amaru Ruiz.'''
doc = nlp_md(article_text)
SVG(data = displacy.render(doc, style="ent"))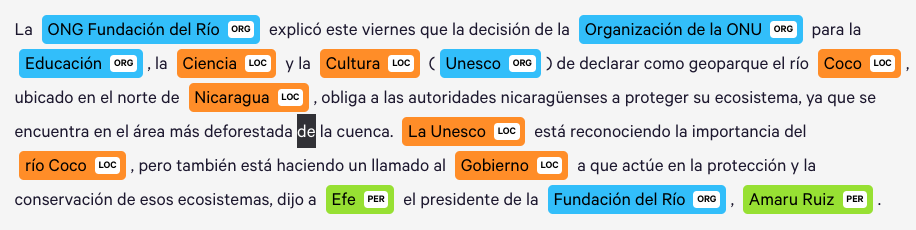
Calcular similitud entre palabras
Una tarea muy comun al momento de realizar trabajo con texto es encontrar la similitud entre muchos documentos o entre oraciones dentro del mismo. Spacy facilita este trabajo al proveer dentro de sus modelos preentrenados funciones que calculan la similitud entre palabras, en este ejemplo veremos el calculo de similitud entre palrabas como perro y gato, perro y reina; veremos como el puntaje asignado tiende a ser cercano a 1 para palabras que tienden a ser de ciertas categorias vs palabras menos probables de aparecer en el mismo contexto.
nlp_md = es_core_news_md.load()
tokens = nlp_md("perro gato banana manzana rey reina")
for token1 in tokens:
for token2 in tokens:
print(token1.text, token2.text, token1.similarity(token2))Algunos resultados a partir del codigo arriba:
| Comparacion | Similitud |
|---|---|
| perro perro | 1.0 |
| perro gato | 0.89080924 |
| perro rey | 0.5446972 |
| banana rey | 0.16387229 |
| banana reina | 0.3148676 |